Linux 性能调优之网络内核参数优化
对每个人而言,真正的职责只有一个:找到自我。然后在心中坚守其一生,全心全意,永不停息。所有其它的路都是不完整的,是人的逃避方式,是对大众理想的懦弱回归,是随波逐流,是对内心的恐惧 ——赫尔曼·黑塞《德米安》
写在前面
- 考试整理相关笔记
- 分享一些 Linux 中网络内核参数调优的笔记
- 理解不足小伙伴帮忙指正
对每个人而言,真正的职责只有一个:找到自我。然后在心中坚守其一生,全心全意,永不停息。所有其它的路都是不完整的,是人的逃避方式,是对大众理想的懦弱回归,是随波逐流,是对内心的恐惧 ——赫尔曼·黑塞《德米安》
网络优化
Linux 网络优化是一个很大的概念,这里讲的优化主要是 传输层和网络层的优化.
Linux和其他主流操作系统中的网络流量被抽象(协议分层与OSI参考模型)为一系列的硬件和软件层次。在每个分层上,发送端添加首部包装信息,经过路由器,接受端分离首部恢复数据。当然路由器的传递也涉及网络层和链路层的首部分离和添加.
简单回顾:
| 分层 | 描述 |
|---|---|
| 应用层 | 应用层涉及协议比较多TELNET,SSH,HTTP,SMTP,POP,SSL/TLS,FTP,MIME,HTML,SNMP,MIB……,主要负责声明目标地址(请求头)以及写入内容(请求报文) |
| 表示层 | 表示层负责将机器特定的数据格式转化为网络标准的传输格式发送出去 |
| 会话层 | 会话层决定采用那种连接方式?同时标记数据包的发送顺序 |
| 传输层 | 传输层即进行建立连接或者断开连接,在两个主机之间创建逻辑上的通信连接,确保数据是否到达,没到达重发,保证数据的可靠性,涉及到的协议包括 TCP,UDP,DCDC |
| 网络层 | 网络层将数据从发送端主机发送到接收端主机。涉及到的协议包括ARP,IPv4,IPv6,ICMP(ping),IPsec等 |
| 链路层 | 包括以太网,无线LAN,PPP,数据链路层负责实现每一个区间内的通信。通信实际上是通过物理的传输介质实现的,数据链路层在传输介质互连的设备进行数据处理。 |
| 物理层 | 硬件层,物理层将数据的01转换为电压和脉冲光传输给物理的传输介质,相互直连的设备通过MAC(Media Access Control,介质访问控制)实现传输。物理层将MAC地址信息的首部附加到从网络层转发过来的数据上,将其发送到网络。 |
数据的流向整体是一个出栈入栈的过程,用应用层开始,包装数据,化整为零,分段传输,然后到物理层为信号传输,这是进栈,到达目标IP,在通过碎片缓存区化零为整,出栈到达应用层。
传输层和网络层的数据流转
数据传输(出站) :
首先,应用程序通过操作系统提供网络套接字API(编程接口)将数据写入到socket文件描述符, 即数据被写入到 socket 文件,然后放到传输缓存中,常见的协议包括TCP(传输控制协议)和UDP(用户数据报协议)。
这是时候操作系统内核从传输缓存中提取数据,根据网络协议规范(TCP/UDP) 封装数据到一个PDU(协议数据单元,TCP段/UDP数据报),网络层会添加 IP 头部,形成 IP 数据报。
将包含 PDU数据单元 的 IP 数据报 放到 设备传输队列 ,等待发送,网络设备驱动程序定期检查传输队列,获取待发送的PDU。驱动程序将PDU数据从内核空间拷贝到网卡设备(NIC)的内存缓冲区
一旦PDU被拷贝到网卡设备的内存缓冲区,网卡设备开始发送数据。数据发送过程可能涉及物理层操作,例如将数据转换为电信号并发送到物理介质(例如以太网)。在数据传输过程中,网卡设备可能会引发中断,通知操作系统数据传输已完成或需要进一步处理。
这里要经过 路由寻址,地址转发,到达目标IP主机,到达目标 IP 之后,会有个入栈操作
接受数据(入站) :
当数据帧到达网卡时,网卡会使用 DMA缓存区 将数据帧复制到接收缓冲区。接收缓冲区是在操作系统内核中为接收数据包而分配的一块内存区域,一旦数据帧被复制到接收缓冲区,网卡会向主机发起硬中断信号,通知操作系统有新的数据包到达。
操作系统内核接收到硬中断信号后,会中断当前执行的任务,并进入硬中断处理程序,在硬中断处理程序中,操作系统内核会调度软中断(软中断是一种延迟处理机制,它允许将数据包的处理推迟到适当的时机,以提高系统性能)来处理接收到的数据包。。
软中断处理程序会从接收缓冲区中读取数据包,并进行必要的处理。这包括解析数据包的各个层级协议头部(例如以太网头部、IP头部等),将数据包移交给IP层进行进一步的处理。
如果数据包大于 MTU(最大传输单元),需要分段传输,这里需要利用 碎片缓冲区 重新组装为原始数据报
内核封装数据到协议数据单元(PDU),对等分层间传输数据的单位,物理层的 PDU 是位(bit),数据链路层的 PDU 是数据帧(frame),网络层的 PDU 是包(packet),更高层的 PDU 是数据报文(message). 一个 PDU 包括上层的数据加本层的数据头部信息。
网络内核调优
通过上面的简单回顾,可以了解到 网络缓存包括内核缓存,每个socket缓存,碎片缓冲区以及网卡的DMA缓冲区。
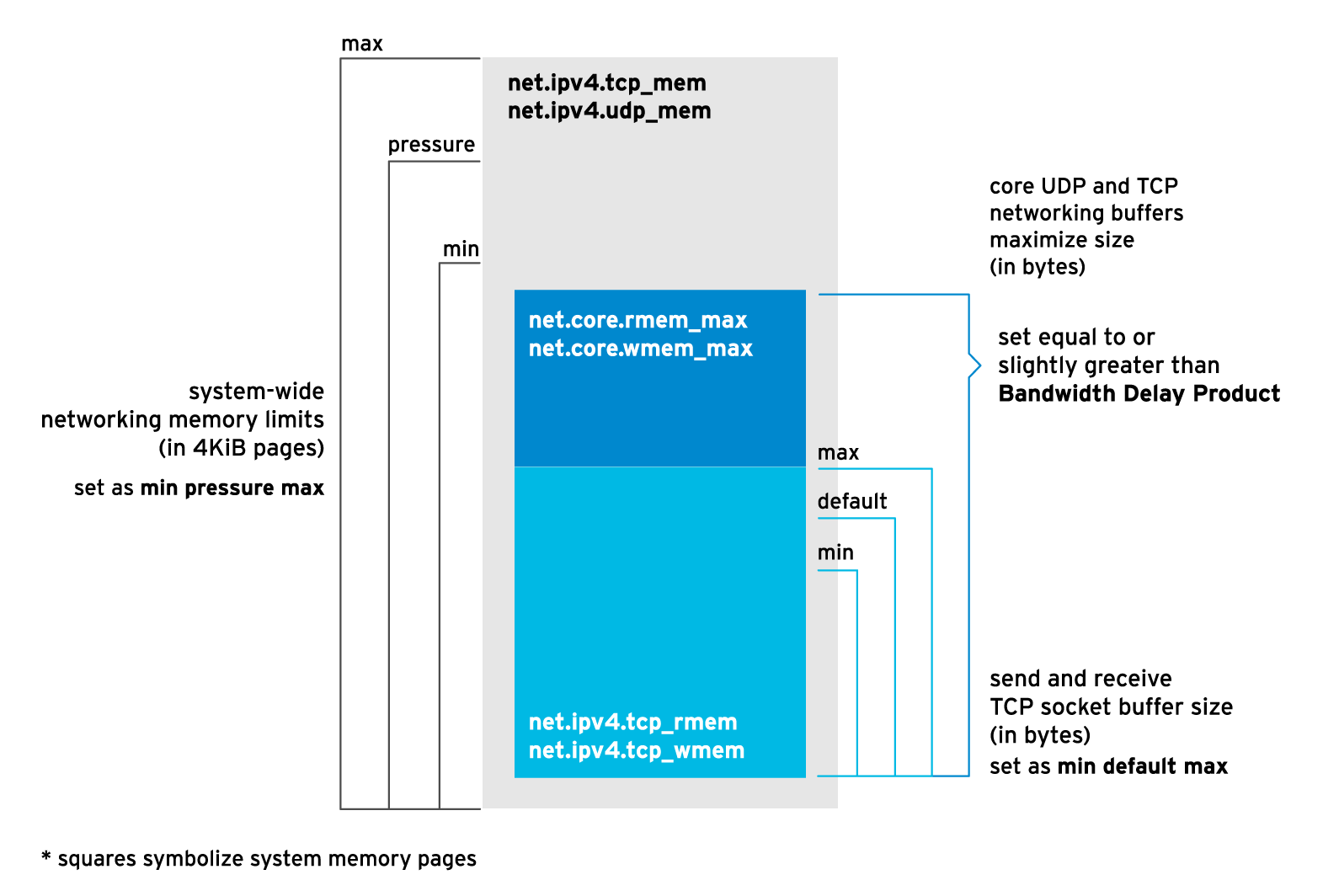
可以通过配置上面不同的缓存区的内核参数达到调优的目的,具体的调优参数配置可以结合上面的图
系统级内核参数(对缓存的动作)
net.ipv4.tcp_mem,net.ipv4.udp_mem(单位是Page 内存页,4K)
分别代表了TCP和UDP的系统层面内存限制的值,即网络连接的内存分配,包括三列:min,pressure,max, net.ipv4.tcp_mem 即我们常讲的 TCP 接收窗口大小
min: TCP/UDP 使用低于这个值时,内核不会释放这些缓存。pressure:当 TCP/UDP 缓存超过这个值时,内核开始释放缓存,减少使用量,直到低于 min 值。max:所有 TCP/UDP 的 sockets 可以使用的最大内存缓存值。
注意:net.ipv4.tcp_mem和net.ipv4.udp_mem是 pages 为单位,不是字节为单位,可以使用 getconf PAGESIZE 查看 page 大小的值(一般是 4096 字节=4K)
查看内存页的大小
1 | ┌──[root@liruilongs.github.io]-[~] |
内核参数位置:
1 | ┌──[root@liruilongs.github.io]-[~] |
对于这两个参数的调优,在使用 sar 来查看链路级的网络性能数据
比如 sar -n EDEV 1 1,显示每个设备的发送和接收错误信息
1 | ┌──[root@vms81.liruilongs.github.io]-[~/ansible] |
| 列 | 说明 |
|---|---|
| rxerr/s | 接收错误率 |
| txerr/s | 发送错误率 |
| co11/s | 发送时的以太网冲突率 |
| rxdrop/s | 由于Linux内核缓冲区不足而导致的接收帧丢弃率 |
| txdrop/s | 由于Linux内核缓冲区不足而导致的发送帧丢弃率 |
| txcarr/s | 由于载波错误而导致的发送帧丢弃率 |
| rxfram/s | 由于帧对齐错误而导致的接收帧丢弃率 |
| rxfifo/s | 由于FIFO错误而导致的接收帧丢弃率 |
| txfifo/s | 由于FIFO错误而导致的发送帧丢弃率 |
当 rxdrop/s和 txdrop/s 存在数据时,可以适当调整上面的内核缓冲内核参数
需要注意的是计算大小的时候,需要使用 当前大小,乘以页数,得到 KB 在 除以 1024 得到 MB。
1 | ┌──[root@liruilongs.github.io]-[~] |
Socket 级别内核参数限制
net.core.rmem_max,net.core.wmem_max
socket接受和发送数据的缓存的最大值,单位为 bytes`` 字节,也存在 net.core.rmem_default和net.core.rmem_min`
1 | ┌──[root@liruilongs.github.io]-[~] |
net.core.rmem_max:该参数定义了套接字接收缓冲区的最大大小。用于存储从网络接收到的数据,等待应用程序读取。较大的接收缓冲区可以提高网络吞吐量和应用程序的性能,尤其对于高速网络或大量数据传输的场景。
net.core.wmem_max:该参数定义了套接字发送缓冲区的最大大小。用于存储应用程序要发送到网络的数据,等待发送到网络。较大的发送缓冲区可以提供更好的网络发送性能,尤其在高负载或延迟网络环境下。
这组内核参数的优化往往结合 BDP 来调整,等于或者大于 BDP 的值,关于 BDP,下文我们会讲。
在 通过 ifconfig 查看系统中所有网络设备的基本性能统计信息。
1 | ┌──[root@vms81.liruilongs.github.io]-[~/ansible] |
关于部分参数的说明
| 列 | 说明 |
|---|---|
| RX packets | 设备已接收的数据包数 |
| TX packets | 设备已发送的数据包数 |
| errors | 发送或接收时的错误数 |
| dropped | 发送或接收时丢弃的数据包数 |
| overruns | 网络设备没有足够的缓冲区来发送或接收一个数据包的次数 |
| frame | 底层以太网帧错误的数量 |
| carrier | 由于链路介质故障(如故障电缆)而丢弃的数据包数量 |
如果 overruns 存在值,可能需要调整上面的内核参数,适当增大。
TCP 级别内核参数
net.ipv4.tcp_rmem,net.ipv4.tcp_wmem
net.ipv4.tcp_rmem 和 net.ipv4.tcp_wmem 用于配置 TCP 套接字的接收缓冲区和发送缓冲区的大小。
1 | ┌──[root@liruilongs.github.io]-[~] |
net.ipv4.tcp_rmem:配置 TCP 套接字接收缓冲区的大小。包含三个整数的列表,表示 最小、默认和最大(以字节为单位)。TCP 接收缓冲区用于存储从网络接收到的数据,等待应用程序读取。
net.ipv4.tcp_wmem:配置 TCP 套接字发送缓冲区的大小。同样,也是包含三个整数的列表,表示最小、默认和最大(以字节为单位)。TCP 发送缓冲区用于存储应用程序要发送到网络的数据,等待发送到网络。
开启一个sokcet,内核会在 min(第一列)和 max(第三列)之间自动设置一个 default(第二列)值
TCP 缓冲区的大小应根据系统和网络的需求进行调整。较大的缓冲区可以提高网络性能,特别是在高负载或高延迟的网络环境中。但是,过大的缓冲区可能会导致内存占用增加或延迟问题。
这两个参数的调优同样参考 `BDP`` 来进行优化
BDP 可以验证缓存大小是否合适,如何计算最大吞吐量时需要多少 缓存 呢?
BDP 是什么
round trip time(rtt 往返延迟时间)本地发送数据包到远程,并从远程返回的时间叫 RTT!
使用 ping 命令可以查看平均往返延迟时间
Linux
1 | ┌──[root@liruilongs.github.io]-[~] |
最后一行可以看到,连接百度有 14 ms 的 RTT 时间,最后的输出结果中可以看到结果信息,假设带宽为 千兆带宽,1000Mbps,即 1Gb/s,假设我们使用的是 千兆网卡
1 | rtt min/avg/max/mdev = 14.190/14.522/15.002/0.344 ms |
1Gb/s * 14.522ms:带宽乘以往返时间(RTT)可以用来估算网络传输的往返延迟(Round-Trip Time Delay)。
将速度单位转换为比特每秒(b/s):1 Gb/s = 1,000,000,000 b/s
将时间单位转换为秒:14.522 ms = 14.522 * 0.001 s = 0.014522 s。。
现在,我们可以计算表达式:1,000,000,000 b/s * 0.014522 s = 14,522,000 b
将比特转换为字节: 14,522,000 bit = 14,522,000 bit / 8 byte = 1,815,250 byte。(1 字节(byte)等于 8 位 (bit),将 14,52 2,000 比特除以 8 以获得字节数。 因此,结果是 1,815,250 字节。
将字节转换为 KiB(二进制制式的千字节),需要除以 1024:
1,815,250字节 / 1024 = 1,772.705 千字节(KiB) / 1024 = 1.731 兆字节(MiB)=1,733.0625兆字节 / 1024 = 0.00169千兆字节(GiB)
那么发送一个数据包等待回应的时间是 0.014522 s 秒,实际上如何没有这个延迟,这个时间段可以发送 1.731 MiB 的数据,这个概念被称为时延带宽乘积(Bandwidth Delay Product,BDP)
互联网的 rtt 值一般会比较大,rtt 值,即往返延迟越低,BDP 的值就越低。
如果 BDP(时延带宽乘积)大于64KiB(64千字节),则在 TCP 连接中建议启用TCP窗口缩放(TCP window scaling)。TCP 窗口缩放是一种机制,用于扩大TCP连接中的传输窗口大小,以适应高带宽和高延迟的网络环境。
设置 tcp_window_scaling 的值为 1
1 | ┌──[root@liruilongs.github.io]-[~] |
如果一个系统需要处理多个并发连接,则每个socket 缓存(rmem、wmem等)的大小只要可以处理单个socket的BDP容量即可。
一般几百KiB基本够用,但默认的208KiB有点小!当然缓存区也不是越大越好
过多的缓存数据包导致了数据包的延迟,延迟抖动和降低了网络的总的通吐量的现象
对于一个速度很快的网络而言,如果配置一个过大的缓存区,也可能导致及时通讯服务类的应用体验很差。
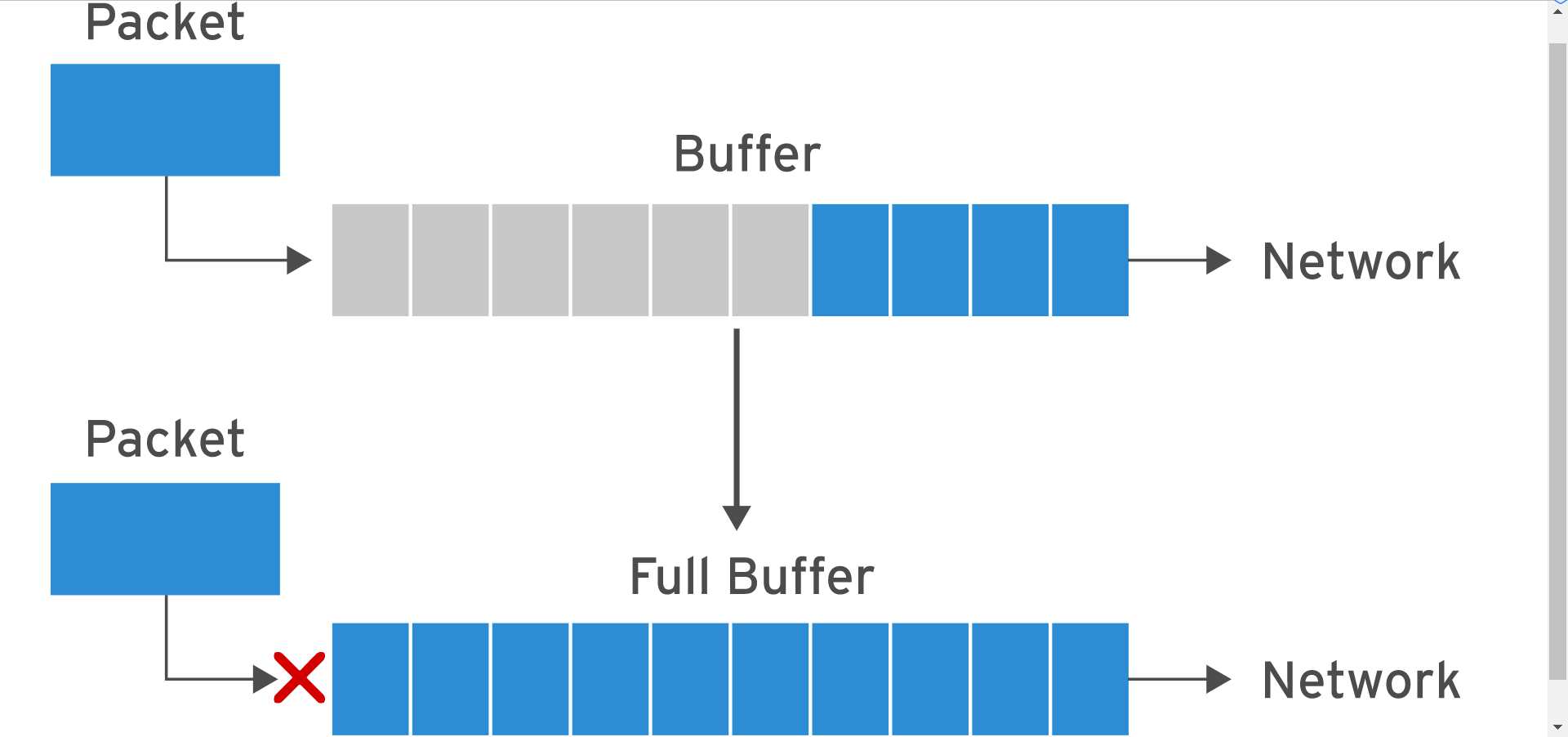
根据 BPD 配置网络调优参数
下面为在 window 机器上 ping 谷歌 DNS ,可以看到 有 169 ms 的 RTT
1 | PS W:\Downloads> ping 8.8.8.8 |
假设当前为百兆带宽,计算 BDP :100 Megabits/s * 0.169 s * 1/8 Byte/bits = =100,000,000 bits/s * 0.169 s * 0.125 Byte/bit = 2,112,500 Bytes
添加 TCP 的读取缓存相关内核参数配置
备份当前内核参数
1 | ┌──[root@liruilongs.github.io]-[~] |
配置调优后的内核参数
修改设置(socket max最大值等于刚才计算的BDP的值,默认值设置为最大值的一半:
1 | ┌──[root@liruilongs.github.io]-[~] |
碎片缓冲区参数
碎片缓存区相关内核参数在一些分片重组丢包的场景需要优化
当前系统的默认参数
1 | ┌──[root@vms100.liruilongs.github.io]-[~] |
net.ipv4.ipfrag_high_thresh 设置了碎片缓冲区的高水位线为 4194304 字节(4 MB)。当碎片缓冲区的使用率超过该阈值时,内核会开始丢弃新到达的碎片。
net.ipv4.ipfrag_low_thresh 设置了碎片缓冲区的低水位线为 3145728 字节(3 MB)。当碎片缓冲区的使用率低于该阈值时,内核会停止丢弃新到达的碎片。
net.ipv4.ipfrag_max_dist 是一个用于限制数据包分片重组的内核参数。它定义了分片偏移(fragment offset)之间的最大允许间隔。当分片之间的偏移超过此阈值时,内核会丢弃分片并阻止重组,以防止可能的攻击和资源耗尽。
net.ipv4.ipfrag_secret_interval 设置了碎片缓冲区的密钥更新间隔为 0,表示不进行密钥更新。
net.ipv4.ipfrag_time 设置了碎片在缓冲区中保持的时间为 30 秒。超过该时间的碎片将被丢弃。
超时
在网络通信过程中,有601个碎片在超时后被丢弃了
1 | netstat -s|grep timeout |
通常发生在碎片重组过程中,当某个碎片的到达时间超过了一定的时间限制(通常是根据 net.ipv4.ipfrag_time 参数设置的)而没有完全到达时,内核会丢弃这个碎片以避免无限等待。
解决方法:调整超时时间
1 | net.ipv4.ipfrag_time = 30 |
frag_high_thresh, 分片的内存超过一定阈值会导致系统安全检查丢包
1 | netstat -s|grep reassembles |
有8094个数据包的重组失败了。这通常发生在数据包分片(fragmentation)和重组(reassembly)的过程中。
增加碎片缓冲区的大小可以提供更多的空间来缓存和重组分片。通过调整 net.ipv4.ipfrag_high_thresh 和 net.ipv4.ipfrag_low_thresh 参数的值来增加缓冲区的大小。
其他网络相关内核参数
常用其他网络相关内核参数(需要修改):
1 | ┌──[root@liruilongs.github.io]-[~] |
上面的配置修改都是临时操作,内核参数的永久修改需要 写在配置文件 /etc/sysctl.conf
开启巨帧
网络上传输的数据包一般包含:包头和数据载荷,一个典型的 TCP/IP 数据包头会包含以太网头部信息,IP 头部信息和 TCP 头部信息。
有这些报头都包含在网络上使用的最大传输单元(MTU)中,单个数据包的最大大小。
例如,使用 TCP 连接使用 52 个字节的协议头。默认 MTU 为 1500 字节,这几乎占开销损失的总容量的 3.5%。
有一种办法是改变通信协议,比如将 TCP 改为 UDP,头部信息就会从 52 字节变成 28 字节(对于 1500 数据包而言,1.9%的开销),但是 UDP 不一定适合所有业务。
另一个方法是增加 MTU 的大小,将 MTU 修改为超过标准的 1500 字节,被称为巨帧(Jumbo Frames)。修改巨帧需要所有硬件设备都支持该功能。
我们可以使用 nmcli 修改网卡的 MTU 大小(下面的例子将 ens33 网卡的 MTU 修改为 9000)
1 | nmcli con modify ens33 802-3-ethernet.mtu 9000 |
如果需要修改 MTU 大小,则需要先确认以下这些设备是否支持巨帧(但不限于这些设备):
- 网卡
- 交换机
- 路由器
一般官方推荐定义的巨帧 MTU 为 9000bytes(字节),但是也有设备支持更大的帧数据。
加大帧大小的好处在于,减少了网络中数据包的个数,减轻了网络设备处理包头的额外开销(可以显著提升性能)。
但缺点是,巨帧至今没有标准化,如果使用不同的 MTU 可能会导致有些设备不兼容,而传统的以太网 MTU 是所有设备都兼容的。
博文部分内容参考
© 文中涉及参考链接内容版权归原作者所有,如有侵权请告知 :)
《 Red Hat Performance Tuning 442 》
https://zhuanlan.zhihu.com/p/502027581?utm_id=0
© 2018-至今 liruilonger@gmail.com, All rights reserved. 保持署名-非商用-相同方式共享(CC BY-NC-SA 4.0)
1.Linux网络优化之从Linux内核epoll/io_uring 到Python(ASGI/WSGI)及Java Tomcat(BIO/NIO)网络IO模型认知
2.Linux网络调优之内核网络栈发包收包认知
3.Linux 性能调优之 OOM Killer 的认知与观测
4.为什么进程的物理内存占用(RSS)不停增长? 利用 BPF 跟踪、统计 Linux 缺页异常
5.如何使用 BPF 监控 Linux 用户态小内存分配:Linux 内存调优之 BPF 分析用户态小内存分配
6.Linux 内存调优之 BPF 分析用户态 mmap 大内存分配
7.如何使用 BPF 分析 Linux 内存泄漏,Linux 性能调优之 BPF 分析内核态、用户态内存泄漏
8.认识 Linux 内存构成:Linux 内存调优之页表、TLB、缺页异常、大页认知

